Foundry Local Meets More Silicon: Expanded AI Runtime and NPU Support
Meng Tang details the new features in Foundry Local, Azure AI Foundry’s powerful local AI runtime. Learn about expanded hardware acceleration support and how to quickly install and deploy AI models on Windows and MacOS.
Foundry Local Meets More Silicon: Expanded AI Runtime and NPU Support
Foundry Local is a high-performance AI runtime stack from Azure AI Foundry that enables developers to build and run cross-platform AI applications efficiently on client devices. This update introduces new capabilities for Foundry Local, reinforcing Microsoft’s commitment to democratizing AI at the edge.
The Evolution of AI Acceleration
- Early on-device AI workloads relied on CPUs, but often suffered from real-time inference limitations due to performance and power constraints.
- The advent of GPUs brought parallelism and improved inference speeds, marking the first leap forward for edge AI.
- NPUs (Neural Processing Units) are now the latest breakthrough, purpose-built for neural network workloads. They deliver higher efficiency and throughput, making advanced AI models feasible on both desktop and mobile hardware.
- This hardware evolution allows AI solutions to be faster, more energy-efficient, and privacy-preserving—often working independently of the cloud.
What’s New in Foundry Local v0.7
- Expanded NPU Support: Now includes Intel and AMD NPUs on Windows 11, joining existing NVIDIA and Qualcomm silicon support.
- Improved Hardware Detection: Foundry Local leverages Windows ML to automatically detect available hardware (NPU, GPU, CPU) and retrieve the correct execution providers, streamlining setup.
- No Bundled Providers Needed: The stack now automatically acquires execution providers, reducing package size and easing installation.
- Cross-Platform Availability: Optimized experiences are available for both Windows and MacOS users.
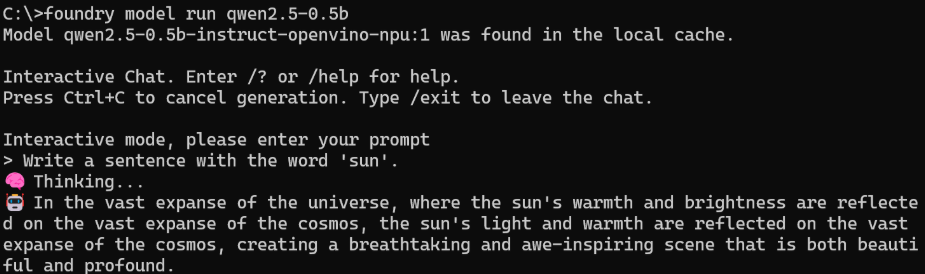
Quick Start Guide
On Windows
- Open Windows Terminal
-
Install Foundry Local:
winget install Microsoft.FoundryLocal -
Run a model:
foundry model run qwen2.5-0.5b
On MacOS
- Open Terminal
-
Install Foundry Local:
brew tap microsoft/foundrylocal brew install foundrylocal -
Run a model:
foundry model run qwen2.5-0.5b
Documentation and More Resources
- Foundry Local Documentation and Samples
- Developers aiming to bring custom models to Windows can learn more about Windows ML (General Availability)
Conclusion
Foundry Local opens doors for developers building high-performance, real-time AI applications on both Windows and MacOS—without being locked to the cloud. The latest release extends hardware compatibility, reduces installation complexity, and ensures edge AI is more accessible than ever.
Article by Meng Tang
This post appeared first on “Microsoft AI Foundry Blog”. Read the entire article here