Reasoning Reimagined: Introducing Phi-4-mini-flash-reasoning for Efficient Edge AI
By Weizhu Chen, Jianfeng Gao, and Liliang Ren. Discover Microsoft’s Phi-4-mini-flash-reasoning model, engineered for efficient, fast reasoning at the edge and on mobile devices, and available now via Azure AI Foundry.
Reasoning Reimagined: Introducing Phi-4-mini-flash-reasoning
Authors: Weizhu Chen, Jianfeng Gao, and Liliang Ren
Microsoft has announced the launch of Phi-4-mini-flash-reasoning, the latest addition to the Phi family of AI models. Experienced in delivering advanced math and logic reasoning, Phi-4-mini-flash-reasoning is specifically engineered for resource-constrained environments such as edge devices, mobile applications, and real-time systems where compute, memory, and latency are often limited.
Key Features and Innovations
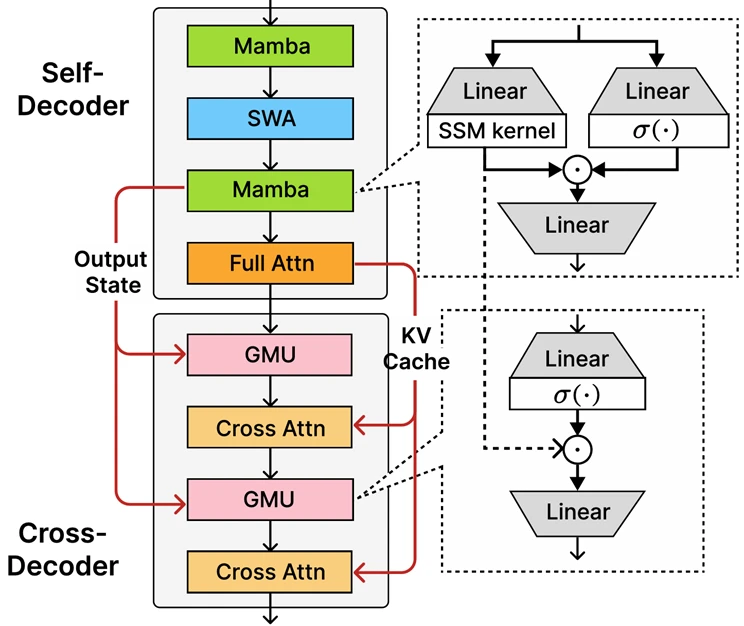
- Hybrid Architecture: Built on the new decoder-hybrid-decoder architecture called SambaY, Phi-4-mini-flash-reasoning leverages the Gated Memory Unit (GMU) to improve information sharing between model layers and foster efficient computation.
- Performance Gains: The architecture provides up to 10x higher throughput and a 2-3x average reduction in latency compared to prior models, making it ideal for responsive, real-time applications.
- Math Reasoning Optimization: This open model, featuring a 3.8 billion parameter design and supporting a 64K token context, results in high-level performance for advanced, logic-intensive tasks such as interactive tutoring or adaptive learning.
- Accessibility: Deployable on a single GPU, and available through Azure AI Foundry, NVIDIA API Catalog, and Hugging Face.
Architecture Details: SambaY and GMU
Phi-4-mini-flash-reasoning’s efficiency is attributed to the new SambaY design:
- Self-decoder: Combines Mamba (State Space Model) and Sliding Window Attention (SWA), using a single full attention layer for context caching with linear time complexity.
- Cross-decoder: Interleaves cross-attention layers and GMUs, significantly reducing computational demands while maintaining robust performance on long-context and math reasoning tasks.
Key benefits:
- Drastically improved decoding efficiency
- Preserves linear prefill time complexity
- Increased scalability and long-context handling
- Up to 10x throughput enhancements
Benchmarks and Performance
- Deployed on a single A100-80GB GPU, the model showcases:
- Lower inference latency across various generation lengths
- Improved throughput during generation
- Superior math reasoning accuracy, outperforming previous Phi models and even larger competitors
Tests conducted with vLLM inference confirm Phi-4-mini-flash-reasoning’s low-latency and high-throughput credentials in real-world inferencing contexts.
Ideal Use Cases
This model’s blend of efficiency and mathematical skill targets key scenarios:
- Adaptive learning platforms requiring immediate feedback
- On-device reasoning assistants—mobile study aids or logic agents
- Interactive tutoring systems that adjust to learner performance
- Lightweight simulations and automated assessment tools with rapid inference needs
Commitment to Trustworthy AI
Phi-4-mini-flash-reasoning is aligned with Microsoft’s responsible AI pillars: accountability, transparency, fairness, privacy, security, and inclusiveness. The development process emphasizes:
- Safety via Supervised Fine-Tuning, Direct Preference Optimization, and Reinforcement Learning from Human Feedback
- Minimizing harmful outputs, maximizing helpfulness, and tailoring safety to broad use cases/cultural contexts
- Encouraging best practices for responsible AI
Read more about these initiatives in Microsoft’s Trustworthy AI and Secure Future Initiative.
Getting Started
- Try the model: Azure AI Foundry
- Explore resources: Find code samples in the Phi Cookbook
- Technical reference: Read the Phi-4-mini-flash-reasoning technical paper
- Community: Join the Microsoft Developer Discord community
- Further learning:
Phi-4-mini-flash-reasoning is available now for experimentation and deployment. For technical details or support, consider joining Microsoft’s open community discussions and ‘Ask Me Anything’ sessions.
This post appeared first on “The Azure Blog”. Read the entire article here