Finding Leaked Passwords with AI: Building GitHub Copilot Secret Scanning
Authored by Ashwin Mohan, this post delves into the creation and refinement of GitHub Copilot secret scanning, highlighting the AI-powered approach to detecting passwords and managing security alerts for developers and security teams.
Finding Leaked Passwords with AI: Building GitHub Copilot Secret Scanning
By Ashwin Mohan
In October 2024, GitHub announced the general availability of Copilot secret scanning—a feature that leverages AI to detect generic passwords in users’ codebases. This in-depth article explores how Copilot secret scanning works behind the scenes, the technical hurdles faced, and the creative strategies that shaped its current functionality.
What is Copilot Secret Scanning?
Copilot secret scanning is part of GitHub Secret Protection, safeguarding millions of repositories by detecting hundreds of secret patterns. Traditional detection relies heavily on regular expressions, which excel at identifying provider-specific secrets but struggle with the variable structures of generic passwords, often causing noisy alerts for security teams and developers.
To address these limitations, Copilot secret scanning uses AI—specifically, large language models (LLMs)—to analyze code context, such as usage and placement of potential secrets. This context-aware analysis results in more precise, actionable alerts that truly matter for repository security.
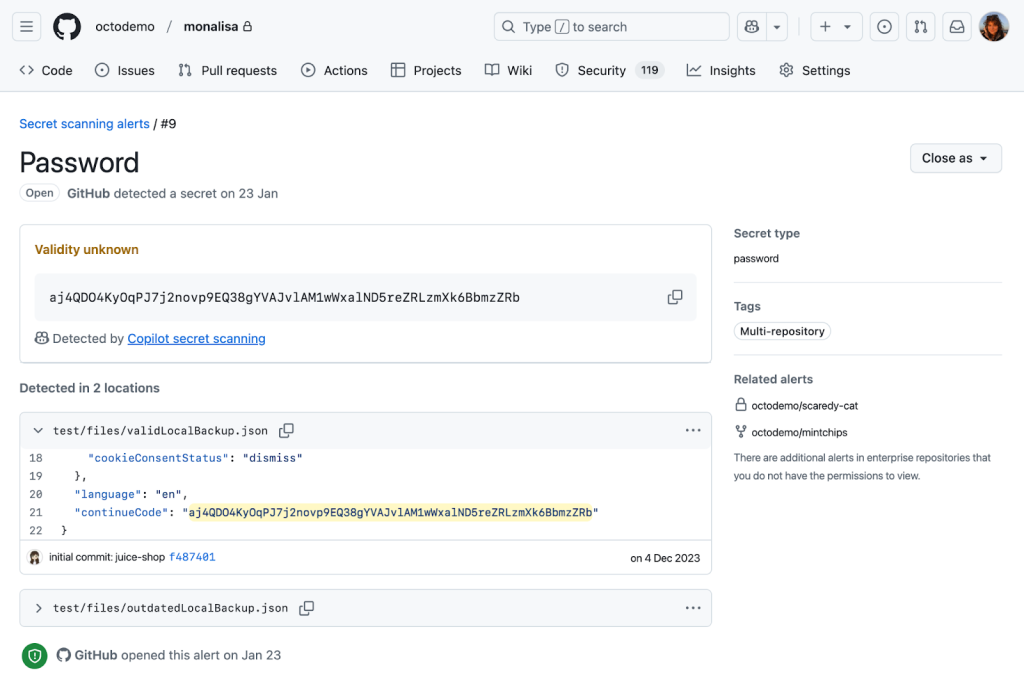
Early Challenges: Unconventional File Types and Structures
The core of Copilot secret scanning lies in prompting a large language model. The prompt provides:
- General vulnerability information (e.g., passwords)
- The source code and location
- Strict JSON output specification for automated processing
The first version used few-shot prompting and GPT-3.5-Turbo for cost-effective scale, with an offline evaluation framework built around manually curated test cases. While initial tests showed promise, private preview participants revealed significant failings: the model struggled with unfamiliar file types and structures, highlighting the complexity of applying LLMs to real-world, heterogeneous codebases.
Iterating on Evaluation and Prompting
Learning from early shortcomings, the team enhanced their evaluation framework by:
- Adding diverse test cases from private preview feedback
- Allowing visual analysis of deviations from model or prompt changes
- Using GitHub Code Security team’s evaluation processes and GPT-4 for new, representative test scenarios
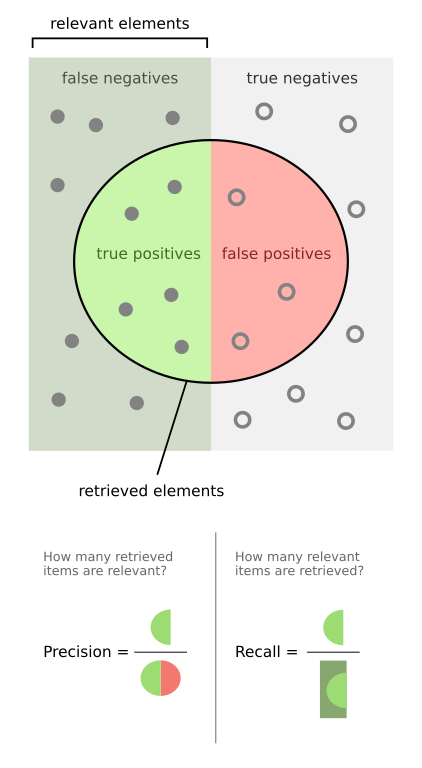
These improvements enabled measurement of both precision (accuracy, reducing false positives) and recall (comprehensive detection, reducing false negatives).
Experiments and Prompt Engineering
A series of experiments were run to refine detection quality:
- Trying alternative models
- Running prompts multiple times and combining results
- Sequencing different prompts/models
- Tackling LLM response non-determinism
Specific strategies included voting (multiple queries for determinism) and leveraging larger models (using GPT-4 as a confirming scanner for GPT-3.5-Turbo findings). Collaboration with Microsoft led to adoption of the MetaReflection technique—a reinforcement learning approach combining Chain of Thought and few-shot prompts for improved precision at minor cost to recall.
The end result was a hybrid approach that moved secret scanning into public preview and set the stage for robust, scalable deployment.
Scaling to Public Preview
Full secret scanning covers both real-time Git pushes and repository histories. Scaling required careful resource and workload management. Efforts included:
- Excluding unlikely or incomprehensible files (media, language files with “test”, “mock”, or “spec”)
- Exploring efficient models (e.g., GPT-4-Turbo, GPT-4o-mini)
- Adjusting context windows for optimal resource use
- Improving tokenization and incremental file processing
The most impactful solution was a workload-aware request management system. Inspired by systems like Doorman and GitHub’s Freno, the approach dynamically allocated LLM resources across different scan workloads, maximizing utilization and preventing both bottlenecks and underuse.
This strategy proved so efficient it was reused in Copilot Autofix and security campaigns.
Mirror Testing and Achieving General Availability
To ensure readiness for general availability, a mirror testing framework ran proposed changes on a subset of public preview repositories. This allowed real-world assessment of alert and false positive rates, absent user impact.
The results were dramatic: some organizations saw a 94% reduction in false positives with negligible loss in true positive detections. This confirmed improved precision and recall, paving the way for a reliable alerting system now available to all GitHub Secret Protection users.
Lessons Learned
Copilot secret scanning is now identifying passwords for nearly 35% of all GitHub Secret Protection repositories. Key takeaways include:
- Focus on Precision: Delivering accurate, actionable alerts remains paramount.
- Diverse Test Cases: Continuous feedback-driven inclusion of real-world examples.
- Resource Management: Scalable performance while controlling costs.
- Collaborative Innovation: Ongoing partnership with GitHub and Microsoft teams drives progress.
These lessons are feeding improvements to Copilot Autofix and other security capabilities. Copilot secret scanning now integrates into security configuration for broad, automated protection.
Forward Path
Continuous monitoring, mirror testing, and customer-driven refinement underpin Copilot secret scanning’s future evolution. The feature is vital in preventing accidental exposure of credentials and complements GitHub’s broader suite of security tools.
Copilot secret scanning is part of GitHub Secret Protection, available enterprise-wide starting April 1, 2025.
This post appeared first on “GitHub Engineering Blog”. Read the entire article here